클러스터란 여러대의 서버를 하나로 묶어 1개의 시스템처럼 동작하게 하는것이다.
클러스터를 구성함으로써 여러 노드에 자동적으로 데이터를 분산하여 높은 성능을 보장하고 특정 서버의 장애가 발생하면 다른 서버로 연결하여 높은 가용성을 보장할 수 있다.
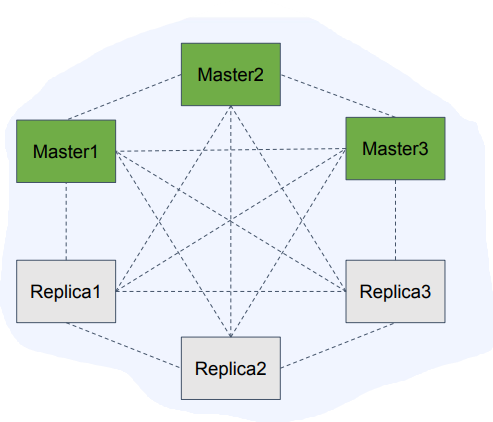
샤딩(Sharding)
샤딩이란 여러 노드 간에 데이터 세트를 자동으로 분할하는 기능이다.
보통 분산 시스템에서 해싱이 사용되는데 Redis는 16384개의 hash slot으로 key공간을 나누어 관리한다.
각 키는 CRC16 해싱 후 16384로 modulo 연산을 해 각 hash slot에 매핑한다.

클러스터 노드는 요청이 온 kwy에 해당하는 노드로 자동 redirect해주지 않고 MOVED에러를 보낸다.
클라이언트는 MOVED 에러를 받으면 해당 노드로 다시 요청해야한다.

이러한 MOVED에러에 대한 재요청으로 인해 성능이 하락할 수 있지만 클라이언트는 key-node맵을 캐싱하므로 대부분의 경우 발생하지 않는다. 때문에 클라이언트는 단일 인스턴스의 Redis를 이용할 때와 같은 성능으로 이용이 가능하다.
Redis클러스터는 데이터 일관성을 일정 부분 포기하면서 고성능의 확장성을 제공하면서 적절한 수준의 데이터 안정성과 가용성을 유지하는 것을 목표로 설계되었다.
클러스터의 데이터 일관성
Redis 클러스터는 높은 성능을 위해 비동기 복제를 하기 떄문에 Strong consistency를 제공하지 않는다.

클러스터의 가용성 - auto failover
일부 master노드가 실패(또는 네트워크 단절)하더라도 과반수 이상의 master가 남아있고, 사라진 master의 replica들이 있다면 클러스터는 failover되어 가용한 상태가 된다.
node timeout동안 과반수의 master와 통신하지 못한 master는 스스로 error state로 빠지고 write요청을 받지 않는다.

예를 들어 master1과 replica2가 죽더라도 2/3의 master가 남아있고 master1이 커버하던 hash slot은 replica1이 master로 승격되어 커버한다.
클러스터의 가용성 - replica migration
replica가 다른 master로 migrate해서 가용성을 높인다.

master3는 replica1개를 뺴도 1개가 남기 떄문에 replica 3-2 는 다른 mster로 migrate가 가능하다.
'백엔드(Back End) > DataBase' 카테고리의 다른 글
| [TIL]20230825 - Redis Pub/Sub (0) | 2023.08.30 |
|---|---|
| [TIL]20230805 - Redis활용하여 캐시레이어 만들기 (0) | 2023.08.06 |
| [TIL]20230804 - Redis의 Data Type (0) | 2023.08.04 |
| [TIL]20230803 - Redis의 특징 (0) | 2023.08.04 |
| [TIL]20230802 - 트랜잭션 격리 수준 (0) | 2023.08.03 |


